This article was originally published in the “Inner Product” column in Game Developer Magazine, November 2005
 I recently programmed the AI for the World Series of Poker, developed by Left Field Productions and published by Activision. I started out thinking it would be an easy task. But it proved a lot more complex than I initially thought.
I recently programmed the AI for the World Series of Poker, developed by Left Field Productions and published by Activision. I started out thinking it would be an easy task. But it proved a lot more complex than I initially thought.
This article for the budding poker AI programmer provides a foundation for a simple implementation of No-Limit Texas Holdem Poker AI, covering the basics of hand strength evaluation and betting. By following the recipe set out here, you will quickly become able to implement a reasonably strong poker AI, and have a solid foundation on which to build. I assume you are familiar with the basic terminology of poker.
TEXAS HOLDEM
The goal of any game playing AI is twofold. The primary purpose is to allow the player to have a fun and enjoyable experience. The secondary purpose, subordinate to the first, is to play a strong enough game to provide sufficient challenge to the majority of players in your intended audience.
POKER DATA TYPES
You will need an implementation of the following data types. I’m going to describe them at the bit/byte implementation level, leaving the high level abstraction up to you.
A “suit” is an integer in the range 0..3, where 0=Clubs, 1=Diamonds, 2=Hearts, 3=Spades
A “rank” is an integer in the range 0..12, where 0 = 2 (deuce), 1 = 3, 11 = King, 12 = Ace. This is the cards in a suit arranged in rank order
A “card” is an integer in the range 0..51, hence
card = suit*13 + rank.
Suit = card/13
Rank = card%13
A “Hand” is a 52 bit data type, where each bit represents a single card. This can be stored as four 16 bit words for ease of use, where each 16 bit word represents the potential cards in one suit (using 13 of the 16 bits) (figure 1)
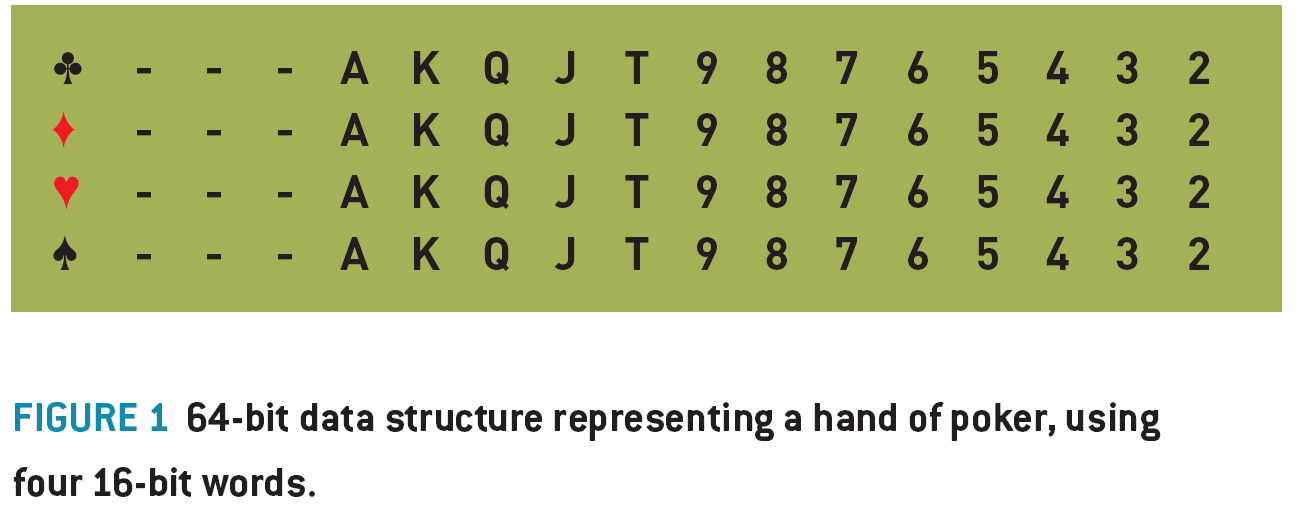
A “Hand Type” is an integer representing the type of poker hand you have, where 0= no pair, 1=pair, 2=two pair, 3=trips, 4=straight, 5=flush, 6=full house, 7=quads, 8=straight flush.
ENCODING HAND VALUES
A “Hand Value” is a 32 bit integer representing the relative value or strength of any hand of cards. By comparing two hand values, you can see which hand is stronger in a game of poker.
The hand value can conveniently be represented as a series of six 4-bit nibbles, where the most significant nibble represents the Hand Type, then the next five nibbles represent the different ranks of the cards in the order of significance to the hand value. (figure. 2)

Example 1: AH QD 4S KH 8C is a “no pair” hand type (sometimes called a “high card” , or in this case “Ace high” ). So, the hand type nibble is set to 0. The remaining nibbles in the Hand Value are filled out with the ranks of the five cards in descending order. (A, K, Q, 8, 4), which translated into rank indices: 12,11,10,6,2 (or C,B,A,6,2 in hexadecimal), and when combined with the hand type (0) in the high nibble, gives us a 32 bit integer: 0x000CBA62.
The individual suits of the cards are basically ignored in the final hand value. The only time suit is significant is when it contributes to a flush. Also, note the top two nibbles of the Hand Value are always zero.
Example 2: 4D JD 3D 4C AD is a pair of fours, with Ace, Jack, Three kickers. The hand type is a pair, (type 1), then the ranks follow, starting with the rank of the pair, then the ranks of the kickers, so 4,A,J,3, which gives us 0x0012C910.
Example 3: 7C, 6C, 5C, 4C, 3D is a straight (type 4). More specifically it’s a seven high straight. The only rank of import here is the seven (rank 5). So the hand value is encoded as 0x00450000. We save ourselves a bunch of instructions in ignoring the four low cards after we’ve determined it is a straight.
Look at the resultant hand values of the above examples, you can clearly see how the better hands always have a higher hand value, making determining the wining hand a simple comparison.
CALCULATING HAND VALUES
What we now need is a function that takes a hand, and returns a hand value. This involves determining the hand type, then inserting the nibbles for the hand ranks, as above.
A hand is four words (clubs, diamonds, hearts, spades) of 13 bits each. 13 bits can be arranged in just 8192 combination, which means we can accelerate the evaluation of a hand by pre-calculating 8K tables of things like the number of bits set in a (13 bit) word (if you have five or more of the same suit, then you’ve got a flush), or the highest card of any straight in the hand. You can also pre-calculate a table of the highest five cards from a particular bit combination, which you can then use to set the kicker cards.
If you calculate ranks = (hearts | diamonds | clubs | spades) then the value ranks is a bit-field with a bit set for every card rank that you have at least one of. The number of bits set here is the number of unique ranks you have. We calculate the number of bits in each of hearts, diamonds, clubs and spades, and subtract the number of bits in the unique ranks, giving the number of duplicated ranks, to be used as the basis of determining what type of hand you have.
Example: if you have 2D AS AH 2C 2H, you can very quickly determine that you have five cards, that there are just two unique ranks, and hence you must have either a full house or four of a kind. A few more simple tests will determine exactly what you have. The entire evaluation function will consist of tests like this, gradually whittling down the possible hand types.
Since the function consists mostly of bitwise operations, table lookups and simple comparisons, it is going to be very fast. It’s also very amenable to fine tuning optimization, and the exact implementation will depend on the target architecture. You may be able to take advantage of some processor specific instructions to greatly improve the efficiency.
CALCULATING HAND STRENGTH
Hand strength is the probability that you will win the hand, given your hole cards, the community cards, and the opponents who remain in the hand. Hand strength is a floating point number between 0.0 (certain loss) and 1.0 (certain win). For example, a HS of 0.33 means you have a 33% chance of winning.
The easiest and most flexibly way of calculating the HS is to simulate the progress of the game a very large number of time, and count the number of those times you win. Say you simulate the game 1,000 times, and in the simulation, you win 423 games, then you have a high degree of certainty of having an approximate HS of 423/1000, or 0.423.
The procedure for simulating a game is very simple:
Create a pack of cards
Set score = 0
Remove the known cards (your hole cards, and any community cards)
Repeat 1000 times (or more, depending on CPU resources and desired accuracy)
Shuffle the remaining pack
Deal your opponent’s hole cards, and the remaining community cards
Evaluate all hands, and see who has the best hands
If you have the best hand then
Add 1/(number of people with the same hand value) to your score (usually 1)
End if
end repeat
Hand Strength = score/number of loops (1000 in this case).
To be more accurate, we have to run our simulation with people dropping out if they are dealt hole cards below a certain threshold. In practice, the determination of if a player stays in or not in a simulation is a probabilistic function of the strength of their hole cards, their table position, their stack size, the blind size and their previous behavior. For now we can just modify the simulation, so after dealing the opponents hole cards, remove any non-blind players with hole cards worse than, say, a pair of sixes. While not particularly elegant, it will still give you a useful number.
POT ODDS
The pot odds number is the ratio of your bet or call to the size of the pot after you bet (the amount you will win). For example, if the bet is $20, and there is $40 in the pot, then the pot odds are 20/(20+40) = 0.333.
RATE OF RETURN
Rate of return is the “on average” proportion of how much you will multiply your bet by, if you stay in the hand.
Rate of Return = Hand Strength / Pot Odds.
The base strategy we implement is to mostly stay in hands with a rate of return greater than 1.
THE FOLD/CALL/RAISE DECISION
For each round of betting the computer needs to decide if it is going to fold, call or raise (The FCR decision). Ignoring the question for the moment of how much to raise for now, then given a Rate of Return (RR), it’s possible to provide a very simple (yet useful) mapping between RR and FCR.
If RR < 0.8 then 95% fold, 0 % call, 5% raise (bluff)
If RR < 1.0 then 80%, fold 5% call, 15% raise (bluff)
If RR <1.3 the 0% fold, 60% call, 40% raise
Else (RR >= 1.3) 0% fold, 30% call, 70% raise
If fold and amount to call is zero, then call.
Don’t pay too much attention to the precise percentages listed above, the numbers will depend on the way you calculate your hand strength, and you’ll want to vary them depending on which betting round you are in. You will also want to vary these numbers to create players with different personalities.
Using this very simple mapping between the RR and the FCR decision can give you a surprisingly reasonable and entertaining player. They will tend to play strong hands, they will occasionally bluff, they won’t scare easy if their hand is good, and they will abandon weak hands when raised, and they will stick around on a reasonable chance of a flush or straight draw, making for entertaining gameplay.
The fact that none of the percentages is 100% is also important. That means you can never deduce the hand strength of your AI opponent based on their actions (unless they fold, where the information does not really help you). If they raise, then they could have any kind of hand strength – probably a good one, but it might be the 1 in 20 times when they are bluffing with a very weak hand.
STACK PROTECTION
The simple rules above work well when your stack of chips is large and the blinds are small. However as your stack shrinks and the blinds increase then the amount of money you need to commit to stay in a hand can become a very substantial proportion of your stack. Also, occasionally other players might go “all-in” , betting their entire stack of chips, so we need some logic to prevent the AI from making bad calls when short stacked.
Say you have AD, 2D and the flop is QC, KC, 2C. So you have a pair of twos, but there is a possible flush out there. There is $500 in the pot and the bet is $100 to stay in against two player, but it’s your last $100. The pot odds are 100/600 = 0.1666, your hand strength is 0.297, so your rate of return is about 1.8. So if you could play this situation over and over again you would make on average an 80% profit each time. However, it’s your last $100, and you have about a 70% chance of loosing everything. Don’t make that bet!
To handle this we can use a simple heuristic, along the lines of:
“If my proposed bet will substantially commit my stack, then don’t do it unless I have a strong chance of winning”
which might be implemented in part by:
“if (stack- bet) < (blind * 4) and (HS < 0.5) then fold”
Meaning if the call would leave you with less than four times the big blind, then don’t call unless you have a greater than 50% chance of winning.
Poker is a complex game, with a surprisingly large number of different types of situations like this that you have to handle somehow. I recommend you have as few special cases as possible, as it reduced the risk of an exploit being introduced into the game via some obscure special case. However, you should anticipate a number of heuristics (rules of thumb) being hard coded into the AI logic.
TESTING POKER AI
Playing a quick single table game of Texas Holdem takes around 30 minutes on average with human players. Ideally you would perform your testing by having human players play against the AI and trying to find problems with it. Unfortunately, due to the random hands being dealt, it’s very easy for one player to simply get lucky and win the game with sub-par logic, or even flawed logic. I’ve found it takes at least ten games to begin to get a clear picture of the qualities of an AI player, and more like a hundred games to be really sure. This often creates an unreasonably burden on the testing department, and introduces a very long delay in getting feedback on AI changes.
The solution is automated testing. The AI should be set up so that different variants of AI can play against each other in a very high speed set of games. You should also code a few simplistic poker AI’s into the mix, such as an AI that always goes all in, or another that simply always raises with a hand better than a pair of fives. Then you set your AI loose against these opponents, and make sure that it wins the appropriate percentage of games. If you coded your evaluation and simulation appropriately, then you should be able to simulate an entire game in about a second. (You might want to reduce the iterations of the simulation a bit to speed up testing).
The best use of your human testers is to try to get them to find an exploit of the AI, then you can codify this exploit into a temporary AI opponent to include in your test suite. You can then tweak your AI until it defeats the exploit, while still being able to defeat all the other (standard) opponents.
MORE WORK
What I’ve set out here is just a foundation for poker AI. By following the process laid out here you will get a reasonably strong and entertaining opponent. Here’s a quick list of the topics you might want to look into
Ӣ Pre-flop hand strength tables
Ӣ Opponent modeling.
Ӣ Implied Odds.
Ӣ Personality modeling
Ӣ Positional play
Ӣ Probabilistic search space
Ӣ Game theory and Nash Equilibrium.
RESOURCES:
– Sklansky, David, The Theory of Poker, 1999, Two Plus Two Publishing. – Provides various discussion of pot odds, implied odds, etc, with many heuristics that might be useful.
– The University of Alberta Computer Poker Research Group:
http://www.cs.ualberta.ca/~games/poker/ A number of research papers on implementing poker AI.
– Hold’em Killer, Evin Peretz, http://www.holdemkiller.blogspot.com/ – A blog on implementing poker AI.
– Poker-Eval, http://freshmeat.net/projects/poker-eval/ – A GPL Licensed poker hand evaluation library.