This article originally appeared in the “Inner Product” column in Game Developer Magazine, February 2006
Next generation game platforms are increasingly making use of multiple processors to deliver more computing power. The Xbox 360 has three symmetrical CPUs running two hardware thread each. The PS3 has one master CPU with seven separate “SPE” processors. The Nintendo Revolution is probably dual threaded. Newer gaming PCs have dual core hyper-threaded processors.
Programmers who were used to programming for a single core are now increasing faced with the challenge of translating their programming skills to a multi-core system. Ideally you want to fully utilize the power of all the processors that you have available to you. A processor idling is a processor wasted. In this article I describe some of the issues involved with this, and discuss a few potential ways developers might architect their engines to more fully utilize the potential processing power.

The simplest option is to just ignore the additional CPU resources, and run all your code from a single thread on a single CPU. (See Figure 1).
All the examples will use this simplified version of the systems in a game engine. Note that the “rendering” portion here is the CPU contribution to rendering (things like high level visibility determination, and preparing the data stream for the GPU to process). The GPU processing is not shown.
Here the flow of execution is very straightforward. We have the game physics, followed by the game logic, and finally the CPU contribution to rendering. Each of these very high-level tasks also has a strict order of mid-level tasks. The physics, for example, first processes the rigid bodies, then the IK animation, and finally the particle systems. This set of systems here is roughly what you might find in a current single processor game.
While this option is obviously not going to take advantage of any of the additional processing power, it does greatly simplify the task of programming the game. Whether this is the best choice depends very much on the type of game you are programming, your schedule, and the programming resources available to you.
Remember the GPU is still responsible for a large portion of the visual quality of your game. If the game contains a relatively low amount of moving and interacting objects (such as a golf game), then you may well be able to get away with using a single processor.
The decision to go single threaded can also greatly simplify the debugging process. Multi-threaded programs can be very difficult to debug. If your schedule is short, and if you’re already got a single-threaded code-base up and running, then it may well be cost effective to simply ignore the extra CPUs, at least for this version of the game.
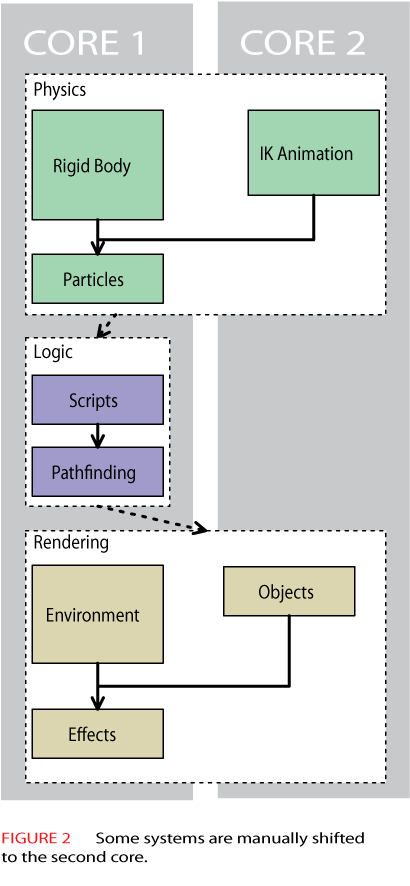
Some mid level tasks are sufficiently decoupled that they can be executed in any order, and even in parallel. If you are able to identify two such tasks, then in theory you should be able to save the processing time that would be taken up by the shorter of the two tasks, by running the two tasks in parallel. (Figure 2)
Here we see the second core has been partially utilized. The rigid body physics and the IK animation are now running concurrently. The time saved here is again the shorter of the two tasks (the IK animation).
The logic portion of the pipeline is not threaded. Typically things such as AI and game object logic are very dependent on the order of execution, and so it is difficult to split an existing AI system into separate threads without introducing a large number of interesting bugs.
Rendering also has some parallelism shown, with the object rendering running at the same time as the environment rendering.
This approach of selectively shifting certain large tasks into separate threads (and onto separate CPU cores), is something you might do as a quick and easy step when retro-fitting an existing engine to be take advantage of multiple cores. The implementation will vary greatly according to the dependencies between systems in your engine. For example, it might be impossible to perform environment rendering at the same time as object rendering if they both share some resource, such as a pool of vertex buffers, which is not thread safe.
The disadvantage is that your have a fairly limited number of pieces of processing with which to play. There are very few ways in which you can arrange things so that your engine will still work, and hence you will end up making poor use of the second CPU core.
Since the parallel tasks are doing very different things, you will also not be making the best use of your shared cache on a hyper-threaded system.
If your high level systems are not suitable for running in parallel, then you should turn to the low level. Many systems comprise of running a similar piece of code over a large number of objects. If the order of processing of the objects is not important then you can start a very short-lived second thread to process half the objects.
You can visualize this as your main thread “forking” into two (or more) threads, each thread processing some of the data, and skipping over unprocessed data, until all the data is processed. The forked thread(s) then terminate, leaving the main thread to continue along the normal path of execution.
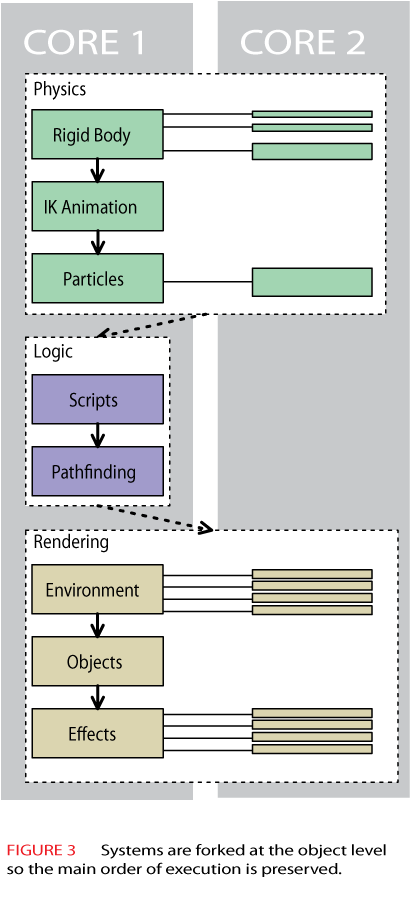
Figure 3 shows how the flow of execution works. The main thread in Core 1 is identical to our simplistic single threaded “solution” in Figure 1. The only difference is that when the main thread is able to process a number of objects concurrently, it forks to process those objects, then continues as a single thread.
Maintaining the original order of execution is a great advantage in simplifying the interactions between systems in your engine. This kind of execution also makes better use of shared caches, since the two threads are running the same code and operate on nearby data.
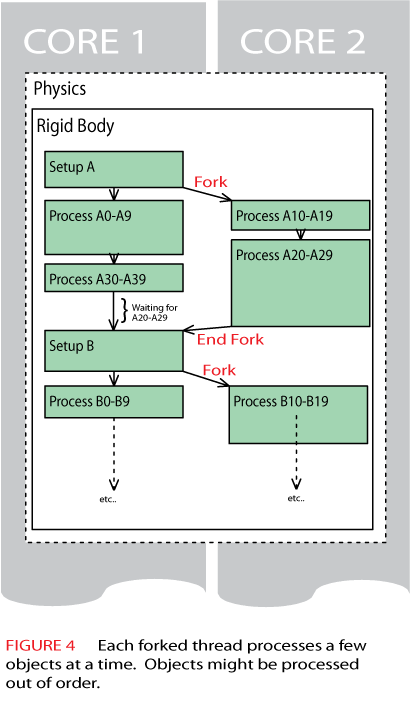
Figure 4 shows how the threads might be forked down at the object level. To reduce overhead, the forks normally process batches of objects. Here we are processing ten objects at a time. First we see a brief setup phase for one set of objects of type A. Then both cores simultaneously begin processing objects, with core 1 processing objects A0-A9 and core 2 processing A10-A19.
In this example, the processing of objects takes different amounts of time. Here core 2 finishes its batch first, and immediately starts on objects A20-A29. Shortly after that, core 1 quickly starts and finishes off A30-A39.
You can clearly see here that the order of processing the objects cannot be guaranteed. It will probably not be the same from one frame to the next, and will very likely differ from one supposedly identical run to the next (say with input recorded for a demo). This can lead to obscure bugs when objects are mostly processed in one order, but very occasionally are processed in a slightly different order, revealing a bug that is very difficult to track down.
If you can work with that, then this is a very powerful technique. It is especially nice in that it scales very well to larger numbers of CPU cores. If you want to target the Xbox 360, then you can simply fork six times, for the six hardware threads on the three cores of the 360.
All the methods so far suffer from Amdahl’s law. Amdahl notes that a large portion of a program execution is unavoidably serial, so you are limited by the time it takes to execute that code, no matter over how many processors you spread the execution of your parallelized code.
It is possible to sidestep Amdahl’s law to some degree by splitting your code into multiple parts, and running them in parallel in what is essentially a multi-stage pipeline.

Figure 5 shows how this looks during a single frame of execution. Both cores are 100% utilized, with core 1 running logic and rendering, while core 2 is fully devoted to physics.
Obviously you are going to run into problems if you try to run logic and rendering on an object in the middle of its physics update. The solution here is to double buffer the output of the physics, and have the logic and rendering actually work with the results of the physics simulation from the previous frame.

Figure 6 shows how this works over the course of three frames. It is easier to understand if you start on the second frame. Here the logic and rendering is running on core 1 using the physics data that was calculated in the first frame. At the same time, core 2 is running the physics simulation that will be used by the logic in frame 3.
This architecture should be very familiar to anyone familiar with the way rendering works on a console such as the PS2. There the GPU is effectively another processor, and (usually) runs in parallel with the CPU, rendering the graphics that were prepared by the CPU on the previous frame. Here we are just extending the pipeline.
In theory you could separate out this pipeline even more if you have addition CPU cores to play with. You could pipeline logic and rendering on two separate threads, so rendering for frame 1 happens at the same time as logic for frame 2 and the physics for frame 3.
But there are number of problems with extending it in this way. Firstly it’s unlikely that you will find the various systems take the same amount of time to execute, so you will be wasting some CPU power. I’ve artificially show the physics taking the same time as logic and rendering combined, but the idea here is that physics usage by the game designers will expand to fill the physics processing capability available.
A potentially more serious problem is the introduction of lag into the game. With a multi-stage pipeline, it could take several frames for the users input to reach the screen. Even on a single threaded game, it will take on average 2.5X the duration of a frame for the input of the player to affect the image seen on screen.
That’s usually acceptable, but if you add another stage to the pipeline, then it jumps to 3.5X the duration of a frame. At that point if you are running at 30fps (shame on you!), then it could take a maximum of 4×1/30 seconds, or 133 milliseconds. That kind of lag is barely acceptable on the internet. Running at 60fps cuts your lag down to 66ms.
A PPU is a physics processing unit, basically a very fast second processor dedicated to the types of computations that are frequently used in physics simulations. A PPU can take the place of core 2 in figures 5 and 6. A PPU should be able to handle vastly more objects than a general-purpose CPU core.
A GPU is a graphics processing unit. But modern GPUs have become so incredibly powerful that it is possibly to do some physics processing. The problem with GPUs is that they are designed to run as a one-way pipe at the end of the pipeline. It’s not really efficient to take the result of calculations from the GPU and feed them back into the start of the pipe.
However, what you can do is separate out that part of the physics that is primarily for cosmetic effects, and need not affect the rest of world. Things such as particles systems, explosions and debris still need physical simulation to move convincingly in the world. The GPU can take over the task of the minimal movement and collision calculations required by these “physics effects” , and incorporate that at the rendering stage. Since this all takes place one the GPU it greatly reduces the bandwidth required to simulate huge amounts of physics effects.
The best of both worlds would be a graphics card that contains both a PPU and a GPU.
A hybrid approach may work very well. There are more complex ways of doing this, and there are many other considerations, but combining the physics pipelining of figure 5 with the task forking of figure 3 will allow you to tune your approach to various target architectures in a reasonably straightforward manner. Pipelining your physics in a separate thread will also allow your engine to eventually take advantage of a PPU processor.
David Wu, Physics in Parallel: Simulation on 7th Generation Hardware.
https://www.cmpevents.com/Sessions/GD/PhysicsinParallel.ppt
Intel Corporation, Threading Methodology: Principles and Practices
http://cache-www.intel.com/cd/00/00/21/93/219349_threadingmethodology.pdf
Henry Gabb and Adam Lake, Threaded 3D Game Engine Basics, Gamasutra,
http://www.gamasutra.com/features/20051117/gabb_01.shtml