VISUALIZING FLOATS.
Floating point numbers permeate almost every arena of game programming. Floats are used to represent everything from position, velocity and acceleration, to fuzzy AI variables, texture coordinates and colors. Yet despite their ubiquitous role in game development, few programmers really take the time to study the underlying mechanics of floating point numbers, their inherent limitations and the specific problems these can bring to games.
This article attempts to explore some of the problems with floats, illustrating certain examples in the hope that programmers will be somewhat less surprised when these problems crop up mid-project, so hopefully you will be better equipped to visualize and deal with these and other related problems.
WHAT IS A FLOAT?
The term “floating point number” can be used to describe many different kinds of number representation. But for games programmers, there are really only two that we need to be concerned with: single and double precision floating point numbers.
By far the most common is the single precision 32 bit floating point number, commonly referred to by its C keyword “float” . Due to the convenient size, and the requirements of the hardware, this is the most popular format for storing and manipulating numbers on all modern gaming platforms. (Although some platforms use 24-bit floats in part of their hardware graphics pipeline, which can greatly magnify the problems discussed below).
A float consists of 32 bits: a sign bit, an 8-bit “exponent” (e), and a 23 bit “significand” (s). For precise details, see reference section.
To visualize the problems with floats, it’s useful to visualize the differences between floats and integers.
Consider how the 32 bit integers represent space. There are 2^32 integers, each one can be thought of as representing a region between two points on a line. If each integer represents a millimeter, then you can represents any distance using integers from 1 mm to 2^32mm. That’s any distance up to about 4295 kilometers (2669 miles), with a resolution of 1 mm. You can’t represent anything smaller than an 1 mm, and objects that are only a few mm in size will have a blocky appearance.
Now picture how we can represent 2D space with integers. If again we are using a resolution of 1mm, you can represent any position in a 4295×4295 kilometer square area, to a resolution of one millimeter. Imagine zooming in closely, and seeing the actual grid of integers.
Now take it one more step, a 3D space can be similarly represented. This time each individual position can be though of as being the space within tiny 1mm cube. Full 3D space is made up of a grid of these identically sized cubes. (Figure 1)

The important thing to remember about these integers defined cubes is that they are all the same size. In 3D Space, the cubes of space near the origin are the same as the cubes of space a mile away from the origin.
FLOATS vs. INTEGERS
Now compare this with floats. First off, start by noting that both integers and floats (in practice) are stored as 32 bit words. As there are only 2^32 possible bit patterns, that means that the number of possible floats is the same as the number of possible integers. Yet floating point numbers can represent numbers in a range from zero to 2^128. (Note: there’s actually a few less floats, as some float bit patterns are Not a Number, or NaN, but we’ll ignore that for simplicity, I’m also going to simplify the treatment of signed quantities)
How this works if fairly obvious if you study the representation of a float. But it’s useful to look into this to gain an understanding of what is going on. The key thing to note is that there are the same number of floating point numbers between each power of two. So from 1 to 2 there are 8388608 (2^23) possible different floating point numbers. From 2 to 4 there are the same number. There’s also the same number of possible floats between 32768 and 65536, or 0.03125 and 0.0625.
Another way of thinking about this is that if you are representing a position with a floating point number, then there are more possible points between the origin and a point 1mm away, then there are possible points between that point and a point on the other side of the planet.
What this means is that the precision of your floating point representation of a position will depend on where you are standing, and what units you are using. If you have units, again, where a floating point value of 1.0 represents 1mm, then when you are standing near the origin (meaning your represented position is close to 0,0,0), then your position can be represented with an accuracy of about 0.0000001mm, which is an incredibly high accuracy.
However, as you move away from the origin, your accuracy begins to decrease. If you are just 1 kilometer away from the origin (1,000,000 mm), then your accuracy drops to 0.125mm, which is still pretty good. But if we move even further away, to say 64 kilometers from the origin, the accuracy drops precipitously to 4mm. This means you can only represent a position with an accuracy of 4mm. That’s a quarter of the resolution that integers give us.
It gets worse, if you keep going out to the edge of the space we could have represented with integers, at 4295 km (about the distance from Los Angeles to New York, the width of the United States), we are at 2^32mm, yet since we can only represent 2^23 bits of precision, our accuracy drops to 2^9mm, or 512mm, about half a meter. So if you use 32 bit floats to represent positions in a game that spanned the continental united states, then on one coast, your positions can only be represented with an accuracy of half a meter (1.5 feet). Clear that is unacceptable, and some other solution has to be found.
SOME SOLUTIONS
Scale your units
– Seems like it would work, but actually does not.
using a floating point value of 1.0 to represent 1 millimeter means that half your usable resolution is in the region between the origin and 1 mm away. Unless your game has a super-shrinking hero in it, you probably don’t need that resolution. If instead, you arrange your units so 1.0 represents 1 meter, then you increase your usable range by a factor of 1000.
Use relative coordinates
– The origin in your universe is in a fixed position, but you can perform all your calculations in a space relative to an origin closer to the action, such as the camera viewpoint. Absolute positions can be stored as floats relative to some other local origin, whose position relative to the universe origin is defined in a more accurate manner (as below)
Use fixed point
– if the important thing is that things look and act the same whether they are near the origin or far away, then you can use fixed point number to store your positions. This is essentially like using integers, but with a sufficiently small unit, so 1 represents, say, 0.1mm, or whatever works for your situation. This can be extended to use 64 bit fixed point for even greater range and accuracy.
Use doubles
– for defining points that are a long way from the origin, you can use double precision floating point numbers. You can either define all positions as doubles, and then convert to a local space for manipulation, or you can define a remote region’s position using doubles, and use relative positions within that using floats.
BOUNDRY CONDITIONS
We often think of polygons and their edges as pure mathematical planes and lines. This is very useful when formulating algorithms to solve certain problems. Consider a simple 2D problem: deciding which side of a line a point is on. This kind of test is often used as part of tasks like seeing if a point is inside a triangle. So, we specify it mathematically: Given a line formed by two points A and B, and a third point P, we calculate the z component of the cross product of AP and AB, Z, such that Z = ((P-A)x(B-A)).z, then if Z is negative then C is on the left, and if Z is positive it is on the right of the line. This is a nice pure mathematical relationship.
To see if a point is inside a 2D triangle, a simple method is to traverse the points of the triangle in a clockwise order, and use the above test to see if the point is to the right of each of the three edges of the triangle. This test can also be used for 3D line-triangle collision detection by first transforming the triangle’s points into the space of the collision line (using the transform that would make the line parallel to the Z axis, reducing the problem to two dimensions).
So, if we have two triangles that share an edge (as most triangles do in video games), and we apply the above tests to them, we should be able to accurately determine which triangle a line lays on. Figure 2 shows two triangles, and the results of performing the test (Z<0) on the line AB that defines the edge they share. It’s a nice clean mathematical split.
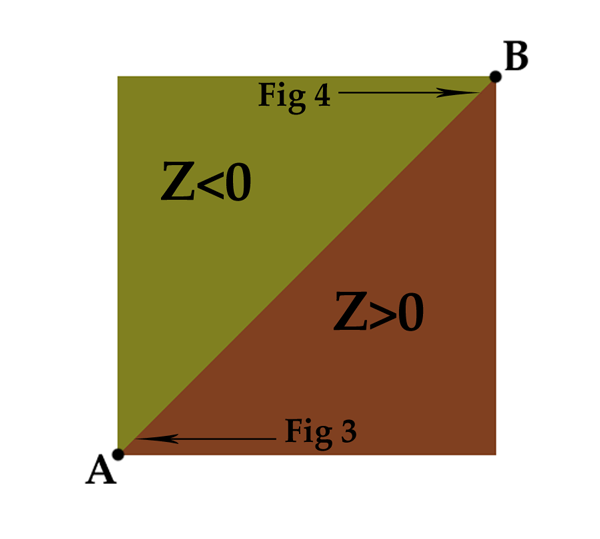
Figure 2 – The line from A=(0,0) to B=(5000,5000) separates points P in this region into two triangles based on the sign of z of the cross product APxAB
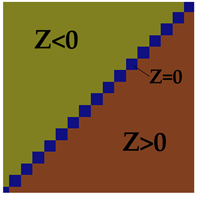
Of course the obvious problem with this test is for points that lay on the line between the polygons, where Z=0. In our pure mathematical world, a line is an infinitely thin region between the polygons. But in the practical world of floating point, the reality is rather different. If you zoom in on the line, down to the level of the individual float regions I described earlier, you will see the line defined by Z=0 is comprised of a series of regions (figure 3). What’s more, if you zoom in on the same line, but further from the origin, you see that the size of these regions increases (figure 4).
The result of this could go two ways, depending on how you implement your logic. If you started out saying “Z>0 implies the point if to the left of the line” , then all the floating point regions that are ON the line (Z=0), will show up as little holes, regions where the collision fails. The quick solution here is to change the test to Z>=0. This eliminates the problem of holes, but creates a new problem, the regions on the line (Z=0) are now shared by both triangles.
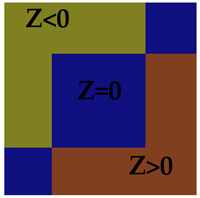
This can create problems if the collision routine returns a list of all the triangles it detects a collision with. The logic might not be set up to deal with being in contact with two different surfaces in the same logic frame, leading to problems like sound effects being stuck on, or events failing to trigger. More commonly though, a line-environment collision test is set to return the closest collision point. Since both polygons will return the same point (which as we see is actually an overlapping region), then the polygon detected will be determined by the order in which the polygons are tested.
Historically the polygons would usually be tested in the same order, however with the increasing prevalence of multi-core architectures, it’s increasing common for programmers to implement some kind of data level parallelism, where the order in which the individual polygons are tested is not guaranteed, and will vary based on the way additional tasks are using the cores, and by the state of the memory cache, which varies from frame to frame. The result can be that the same collision test performed on the same data can return either of two polygons in a seemingly random manner. Most likely it will return one polygon 99.99% of the time, with the other polygon cropping up extremely rarely. This can result in a “Heisenbug” , which can be incredibly difficult to track down, since it surfaces vary rarely, the conditions can be impossible to replicate, and introducing test code can “fix” the problem.
There are a number of solutions to this. You can change your multi-core data sharing algorithm so that polygons that might share an edge are always submitted in the same batch. That would still leave you with the potential problem of two polygons being returned with the same collision point. You could also try to guarantee that the regions on the line Z=0 always belong to one polygon of the other, which you could do by flagging the edges of a polygon so one side uses Z<0 and the other effectively uses Z>=0.
SUMMARY
Floats are a very useful way of representing numbers. But remember that they do not perfectly represent the mathematical world that you use when creating algorithms. Floating point coordinates represent regions in space rather than points. Those regions get a lot bigger as you get further from the origin, and eventually create noticeable artifacts such as jittering and visible seams. This is an important consideration if you are attempting to scale an existing engine to one that supports a much larger world. Floating point inaccuracies can lead to indeterminate boundary regions of variable size. These need to be dealt with explicitly to avoid Heisenbugs.
References:
Wikipedia floating point entry: http://en.wikipedia.org/wiki/Floating_point
Christer Ericson, Real Time Collision Detection, Chapter 11: Numerical Robustness. Morgan Kaufmann, 2005.
Peter Freese, Game programming Gems 4, Chapter 2.3, Solving Accuracy Problems in Large World Coordinates , Charles River Media, 2004
Great article, Mick. The only issue I might raise is that in your proposed solutions, scaling your units doesn’t solve the problem at all. Using your example of Los Angeles to New York, it doesn’t make a bit of difference whether 1.0 represents 1 meter, 1 kilometer, or 1 parsec. Your accuracy will still only be +/- 0.5 meters at the distance of New York to LA from the origin. The issue here is that your accuracy is limited by your precision at that range. Shifting your origin to Kansas City is actually a better solution, since you’ll halve the distances to either of the coast cities (and make use of the sign bit).
Comment by Peter Freese — February 27, 2007 @ 4:51 pm
Well, drat! That is not intuitively obvious. I’ll have to write a follow-up now. Thanks Peter.
Comment by Mick West — February 27, 2007 @ 6:56 pm
That came up at a meeting here as well – adjusting the scale won’t do a thing since all entities are scaled equally, so the accuracy you have will be scaled as well. I guess you could try scaling to a boundary to maximize the accuracy a little – ie. center your world, but make sure the extents are at -1 & 1, say, and not -0.9 & 0.9.
Comment by Paul Robinson — April 3, 2007 @ 10:39 am
I don’t know what I was thinking. I must be getting old.
Comment by Mick West — April 3, 2007 @ 12:59 pm
I have similar concerns about using floats as color component values in HDRI. Color is equally dependant on the relative value between two “consecutive” colors as it is on the absolute value of that color. If there isn’t enough resolution in our color data, then we end up with nasty gradients.
As you probably already know, HDRI seeks to use values outside of the [0.0 1.0] range in order to represent light saturation. Almost a full 1/8th of all usable 32b floating point values (because of the NaN and inf definition, there are only (2^32 – 2^24) usable values, and only half of them are positive) fall in the [0.0 1.0] range, and as you demonstrated, the values get much worse the further out you get.
It’s unfortunate that the latest graphics hardware is now hardwired to exclusively use floats in shader operations.
Comment by Sean T. McBeth — August 13, 2007 @ 5:18 am
Great article! Very nice
Comment by „¥â᪨¥ ¨£àë — January 18, 2009 @ 9:43 am
In your FLOATS vs. INTEGERS part you got the precision wrong. Remember the implicit bit in floating point numbers. 32 bit floats have 24 bits of precision. (If you want to store integers in a float, you can accurately represent all integers from 0 to 16777216. As you said, between any 2 powers of two there are 8388608 possible numbers, so from 8388608 to 16777216 you have all the needed 8388608 integers. From 0 to 8388608 you also have all the integers plus lots of numbers inbetween. From 16777216 to 33554432 you only have the even integers)
So your precision up to 2^32mm becomes 256mm. Using the sign bit (by centering the world, as mentioned), your precision increases to 128mm. Still not great, but much more useful than 512mm. And you could use doubles :)
Comment by Erik Lien — March 9, 2009 @ 7:07 pm
Great article, Mick!
Comment by Любитель мини-игр — March 19, 2009 @ 5:42 am
Enjoyed reading this article, nice one Mick
Comment by Catherine Ellis — October 25, 2009 @ 5:54 pm
I think commenter erik lien is right. Might want to doublecheck that Mike.
Comment by dog health information — November 21, 2009 @ 4:27 pm
thanks a lot for the interesting and informative post.
Comment by burning calories — January 6, 2010 @ 10:38 am
Great job, Mick! This article makes people to think about stuff that they use every day but have no idea how it works.
I would like to add a little note about scaling. In fact using large scaling e.g. nanometers will give you _slightly_ better accuracy than your get using parsecs. But the accuracy ratio of different scalings will newer exceed 2. And there is no matter is it float or double.
Comment by Fyodor — March 23, 2011 @ 6:52 pm