This article originally appeared in Game Developer Magazine, November 2006.
STYLUS CONTROL FOR GAMES
Until recently the majority of games have been controlled with either a handheld “sticks and buttons” controller (on consoles), or a combination of keyboard and mouse (on the PC). Two factors are changing this. Firstly, the casual game market’s emphasis on simple and accessible gameplay has resulted in a large number of games that are mouse-only, and that only use single clicks of one mouse button. Secondly, the release of the Nintendo DS has hugely increased the potential audience for games that are controlled by a touch screen and a stylus. The two factors converge in Nintendo’s branded “Touch Generation” games, which are essentially casual games for the DS that are played with a stylus. An additional factor is the increase in the installed base of tablet PCs and the related emerging market of ultra-mobile PCs (like the Microsoft “Origami” spec) that use touch screens with a stylus or a finger as their primary input device.
This article discusses a few of the programming and control design issues involved with implementing stylus control (and the related single-button mouse control) in a game.
DEFINE YOUR ROLE
What should the role of programmer be in implementing stylus player control? Are you implementing the player control, or implementing tools that allow someone else to implement it? Programmers have always been a key part of implementing player control, and it is one of the few remaining areas where the programmer is directly involved in the most critical aspect of gameplay – the interface between the player and the game.
Yet, like most aspects of game development, even player control is shifting to a more data-driven approach, where a game designer is able to define the player control with some script language or table of data. Problems arise with this approach when the capabilities supplied by the programmer do not adequately match the needs of the designer. This is especially problematic when the programmer is tasked with implementing a specific set of input functionality, and then handing it over to the designer before moving on to other tasks.
The implementation of player control is an organic, exploratory task, especially when dealing with a controller (such as a stylus) that is new to the team. It is inevitable that unforeseen inadequacies will be found in any control scheme technical design, and that subtle control bugs will crop up throughout the course of the project. Hence it is highly recommended that a significant portion of the programmer’s time is allocated to make refinements and fixes. This is especially true if the programmer is working on the actual player control, and not just the underlying code. In that situation, the programmer needs to be free to make very rapid changes to the player control when the need arises.
The role of the programmer is unique in this area, since the effective implementation of intuitive player control requires an understanding of what is going on at a per-frame level. This is not something the designer is typically experienced with, and hence they will heavily rely on the programmer to explain what is going on when “this just does not feel right” . Again, the programmer is not simply implementing a control specification; they are an integral part of organically developing a seamless user experience.
MOUSE vs. STYLUS
At first glance it may seem that a stylus is just a mouse that draws on the screen, and indeed with a tablet PC, you can use the stylus pretty much as you would use a mouse. Since you might be asked to develop a game that works well with a mouse and stylus (or convert from one system to another), you need to think about what the differences are.
Other than other obvious physical distinctions, the fundamental logical difference is that with a stylus there is no need for a permanent cursor. A mouse is always moving a cursor object around the screen, but the stylus is its own cursor. The leads to the next major difference: you don’t always know where the stylus is. With a mouse, if you move it from one position to another, say to click on one icon, then another, the code can detect the movement of the mouse between these two icons, and use that information as hints to the player control. With a stylus on platforms such as the Nintendo DS, it is invisible when lifted off the screen, and essentially vanishes from one point to appear on another. On platforms like the tablet PCs, the stylus can be detected moving in the air an inch or so above the surface, but can still move out of range, and re-appear somewhere else.
DEBUG BEFORE CODING
The single most important tool in implementing player control is the ability to visualize exactly what is going on. The very first thing you should implement is the displaying of the device input data in an easily understandable form. This need not be complex. In the figures accompanying this article I just use alternating red and black diamond shapes at every recorded stylus position, with a line drawn between them.

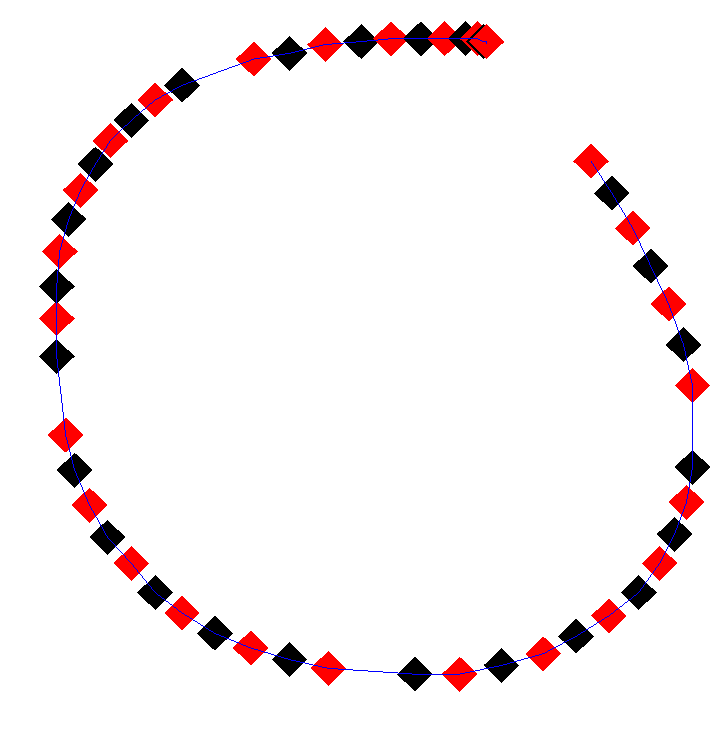
This visualization will give you a good initial idea of the type of input you will be handling, and can highlight unexpected issues with either the hardware, or with the driver layer you are using to read the stylus or the mouse. For example, figure 1 shows approximately the same stroke performed by two different mice; each read the same way by simply handling the WM_MOUSEMOVE messages. In figure 1a you notice the points are fairly evenly spread, and the curve is reasonably smooth, but there are a few small kinks here and there. Compare with figure 1b, there are two differences, firstly the line itself is smoother, with fewer kinks, secondly, and more importantly, there are four samples “missing” from the data.
The smoothness of the line can be attributed to the second mouse being an expensive wireless laser optical mouse, whereas the first mouse was the cheap ball-based one that came with the computer. The gaps in the line could be anything, maybe a driver bug, or a problem in some higher layer, but the important thing here is this simple visualization reveals these problems before you start coding.
DEVELOP A LANGUAGE
For efficient communication between programmer and designer, you need to agree on a common language. The fundamental, low-level, building blocks of player controls are the device “events” you are probably already familiar with. Specifically: the movement events and the contact or button events. But at a higher level, stylus control consists of a series of “strokes” .
A “stroke” is the path defined by the collection of points that the stylus moves through between a down event and an up event. A stroke can be as short as a single tap on the screen (equivalent to a mouse click), or can be a long stroke covering the entire screen that indicates something like the path a weapon should take, or a set of objects to be selected.
Other high level control events are game specific. A “throw stroke” might indicate throwing something in a particular direction. Words such as “tap” , “drag” , “gesture” , “path” , etc, have different meanings depending on the game type, and it is important to establish exactly what you mean when discussing player control.
DIFFERENT STROKES
In my article “Pushing Buttons” (Game Developer, May 2005), I discussed the problem of “sloppy thumb” , where different users hold the controller in different ways, which leads to different patterns of input that the programmer needs to deal with. Similar factors apply to stylus control and simple mouse control.
With a stylus, people can hold it at different angles, which effects the amount the stylus can slip when making contact with the screen. The force applied when tapping can also affect the shape of the resultant stroke. A light handed person may give a nice smooth line, whereas a more heavy-handed person, or someone with poor motor control, may start off the stroke inadvertently in the wrong direction as the style makes contact.

In figure 2, we see three different people attempt the same simple left-right stroke. In Figure 2a, the player gives us a nice clean stroke, holding the stylus firmly yet precisely, and moving his hand smoothly and cleanly. In figure 2b, the player has hit the screen hard with the stylus, but is holding it loosely, causing it to slip upwards slightly at the start of the stroke. In 2c, the start of the stroke is again indeterminate, as here the player has tapped the stylus down hard, and paused for a fraction of a second before starting the stroke. At the end of the stroke the player has slowed their movement and the angle of the stroke tends upwards. This ending is more typical of a left handed player who holds their stylus with a firm overhand grip, as they would a pen.
What is the programmer to make of these strokes? It depends on what’s going on in the game, but a common control element is “throwing” something, or shooting a missile in a particular direction. We need to translate the stroke into a direction vector. Two obvious approaches are to either use the vector from the first point in the stroke to the last, or to use the vector formed as the average from all the individual components of the stroke.
But as we can see from the strokes, the results of these calculations would result in a direction vector that is not in line with the intent of our sloppy players. Our precise player in 1c would be fine, but in both 2b and 2c, the resultant vector would tend upwards.
A possible solution here is to simply chop off the start and the end of the stroke by a certain amount, ignoring, say, the first and last 10% or maybe 0.05 seconds of a stroke. But a more sophisticated solution would be to try to identify the “straight” portion of the stroke, which we can easily recognize ourselves, but is a little more complex to program.
Whether you actually want to do this depends on the type of game, and the intended audience. Some games such as golf, bowling or curling might depend on the nuance of a stroke for fine control of ball spin, and so the degree of slack you want to give the player would be less. But in ball tossing games such as Magnetica or Luxor, all you want is a direction vector.
ACCELERATION INFORMATION
The raw vectors that form a stroke tell you where on the surface the player moved his stylus, and how fast. But by looking at the acceleration information in the stroke data, the programmer can gather information that indicates what the user was doing before and after the actual stroke.

Consider the two strokes in figure 3. They both cover about the same distance in the same direction. But in 3a, there is significant acceleration at the start of the stroke, and deceleration at the end. This indicates the player deliberately made the stroke from one point to another, and the stylus was not really moving before and after the stroke. In 3b, the stroke is the same speed throughout, indicating the player was moving the stylus bother before and after the stroke at the same speed. This is like the player moving the stylus through the air, dipping it down to briefly touch the surface and continue.

These two movements are very different, yet the interpretation of the strokes may or may not be different, depending on the type of game.
SUMMARY
Game control using strokes from a stylus or a mouse is increasingly common. The programmer’s technical knowledge makes him an integral part of the design process and the organic implementation of that player control. Visualization is vital. Players have different input styles and mental expectations of stroke control, and by accommodating as many styles as possible without compromising coherent controls, you will expand the potential market and the conversion rate for your game.